Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
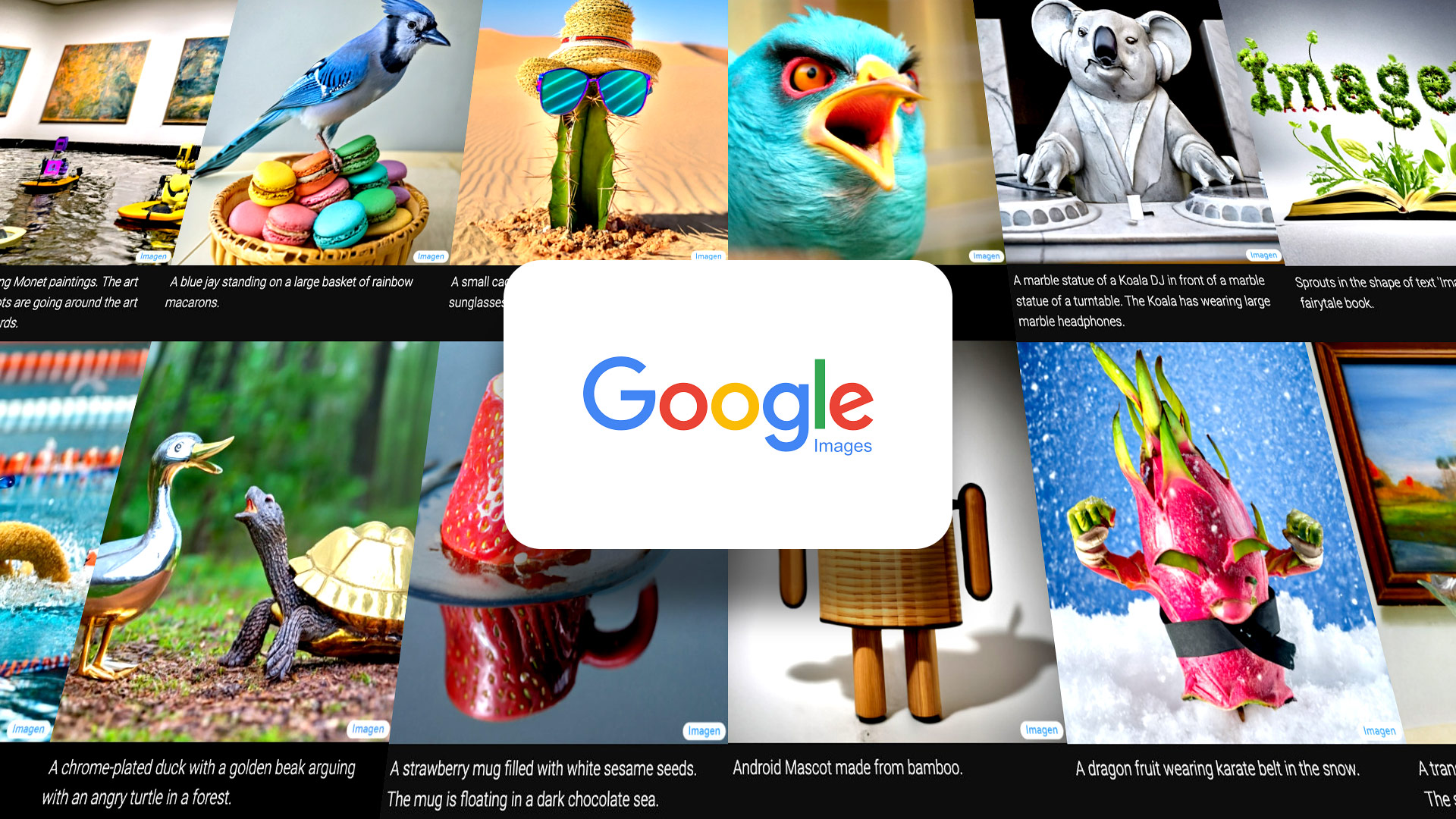
Há uma nova tendência em IA: geradores de texto para imagem.
Alimente esses programas com qualquer texto que desejar e eles gerarão imagens notavelmente precisas que correspondem a essa descrição.
Eles podem combinar com uma variedade de estilos, de pinturas a óleo a renderizações CGI e até fotografias, e – embora pareça clichê – de muitas maneiras o único limite é sua imaginação.‘
Até o momento, o líder no campo foi o DALL-E, um programa criado pelo laboratório comercial de IA OpenAI (e atualizado em abril ). Ontem, porém, o Google anunciou sua própria versão do gênero , Imagen, e acabou de derrubar DALL-E na qualidade de sua saída.
A melhor maneira de entender a incrível capacidade desses modelos é simplesmente examinar algumas das imagens que eles podem gerar. Há alguns gerados pelo Imagen acima e ainda mais abaixo ( você pode ver mais exemplos na página de destino dedicada do Google ).
Em cada caso, o texto na parte inferior da imagem era o prompt inserido no programa e a imagem acima, a saída. Só para enfatizar: isso é tudo o que é preciso. Você digita o que quer ver e o programa gera. Bem fantástico, certo?



Mas, embora essas fotos sejam inegavelmente impressionantes em sua coerência e precisão, elas também devem ser tiradas com uma pitada de sal. Quando equipes de pesquisa como o Google Brain lançam um novo modelo de IA, elas tendem a escolher os melhores resultados. Portanto, embora todas essas imagens pareçam perfeitamente polidas, elas podem não representar a saída média do sistema de imagens.
Muitas vezes, as imagens geradas por modelos de texto para imagem parecem inacabadas, manchadas ou borradas – problemas que vimos com imagens geradas pelo programa DALL-E da OpenAI. (Para saber mais sobre os pontos problemáticos dos sistemas de texto para imagem, confira este tópico interessante do Twitter que aborda os problemas com o DALL-E . Ele destaca, entre outras coisas, a tendência do sistema de interpretar mal os prompts e lutar com ambos texto e rostos.)
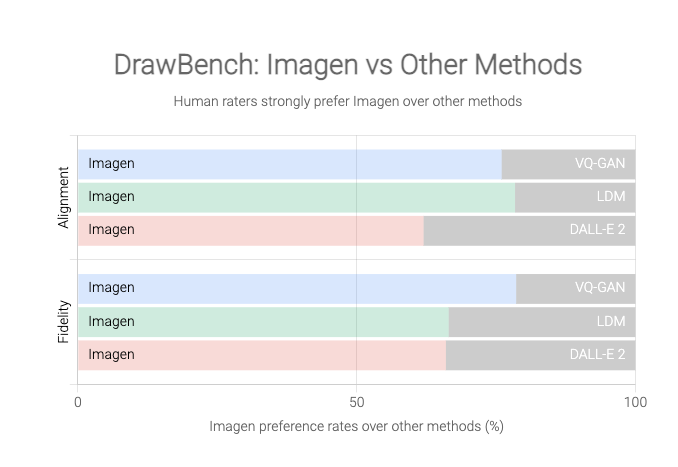
O Google, no entanto, afirma que o Imagen produz imagens consistentemente melhores que o DALL-E 2, com base em um novo benchmark criado para este projeto chamado DrawBench.
O DrawBench não é uma métrica particularmente complexa: é essencialmente uma lista de cerca de 200 prompts de texto que a equipe do Google inseriu no Imagen e em outros geradores de texto para imagem, com a saída de cada programa julgada por avaliadores humanos. Conforme mostrado nos gráficos abaixo, o Google descobriu que os humanos geralmente preferiam a saída do Imagen à dos rivais.
No entanto, será difícil julgar isso por nós mesmos, pois o Google não está disponibilizando o modelo Imagen ao público. Há uma boa razão para isso também. Embora os modelos de texto para imagem certamente tenham um potencial criativo fantástico, eles também têm uma gama de aplicações problemáticas. Imagine um sistema que gera praticamente qualquer imagem que você goste sendo usada para notícias falsas, hoaxes ou assédio, por exemplo. Como observa o Google, esses sistemas também codificam preconceitos sociais, e sua saída é muitas vezes racista, sexista ou tóxica de alguma outra forma inventiva.
Muito disso se deve à forma como esses sistemas são programados. Essencialmente, eles são treinados em grandes quantidades de dados (neste caso: muitos pares de imagens e legendas) que eles estudam em busca de padrões e aprendem a replicar. Mas esses modelos precisam de muitos dados, e a maioria dos pesquisadores – mesmo aqueles que trabalham para gigantes de tecnologia bem financiados como o Google – decidiram que é muito oneroso filtrar essa entrada de forma abrangente. Assim, eles extraem enormes quantidades de dados da web e, como consequência, seus modelos ingerem (e aprendem a replicar) toda a bile odiosa que você esperaria encontrar online.
Em outras palavras, o velho ditado dos cientistas da computação ainda se aplica ao mundo alucinado da IA: “LIXO ENTRA, LIXO SAI“.
Como os pesquisadores do Google resumem esse problema em seu artigo : “[Os] requisitos de dados em larga escala dos modelos de texto para imagem […] levaram os pesquisadores a confiar fortemente em grandes conjuntos de dados extraídos da web, em sua maioria sem curadoria [. ..] As auditorias de conjuntos de dados revelaram que esses conjuntos de dados tendem a refletir estereótipos sociais, pontos de vista opressivos e associações depreciativas ou prejudiciais a grupos de identidade marginalizados.”
O Google não entra em muitos detalhes sobre o conteúdo preocupante gerado pelo Imagen, mas observa que o modelo “codifica vários preconceitos e estereótipos sociais, incluindo um viés geral para gerar imagens de pessoas com tons de pele mais claros e uma tendência para imagens retratando diferentes profissões para se alinhar com os estereótipos de gênero ocidentais”.
Isso é algo que os pesquisadores também descobriram ao avaliar o DALL-E . Peça a DALL-E para gerar imagens de uma “comissária de bordo”, por exemplo, e quase todos os sujeitos serão mulheres. Peça fotos de um “CEO” e, surpresa, surpresa, você recebe um monte de homens brancos.
Por esse motivo, a OpenAI também decidiu não liberar o DALL-E publicamente, mas a empresa dá acesso a testadores beta selecionados. Ele também filtra certas entradas de texto na tentativa de impedir que o modelo seja usado para gerar imagens racistas, violentas ou pornográficas. Essas medidas restringem de alguma forma possíveis aplicações prejudiciais dessa tecnologia, mas a história da IA nos diz que esses modelos de texto para imagem quase certamente se tornarão públicos em algum momento no futuro, com todas as implicações preocupantes que o acesso mais amplo traz. .
A própria conclusão do Google é que o Imagen “não é adequado para uso público no momento”, e a empresa diz que planeja desenvolver uma nova maneira de avaliar “viés social e cultural em trabalhos futuros” e testar futuras iterações. Por enquanto, porém, teremos que nos contentar com a seleção otimista de imagens da empresa – realeza de guaxinins e cactos usando óculos escuros. Isso é apenas a ponta do iceberg, no entanto. O iceberg feito das consequências não intencionais da pesquisa tecnológica, se a Imagen quiser tentar gerar isso.
Matéria original:
theverge
Se gostou deste artigo não esqueça de compartilhar com seus amigos.



